Training YOLOv11 Classification (Kuzushiji Recognition) Using mdx.jp
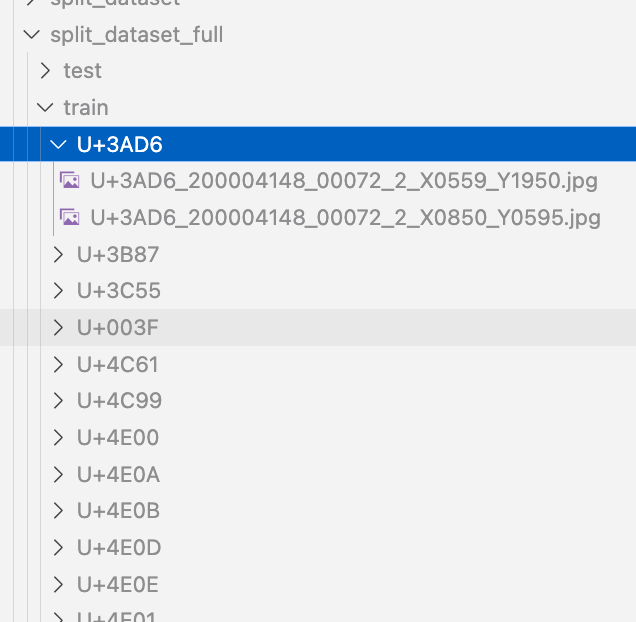
Overview We had the opportunity to train a YOLOv11 classification model (for kuzushiji/classical Japanese character recognition) using mdx.jp, so this article serves as a reference. Dataset We target the following “Kuzushiji Dataset”: http://codh.rois.ac.jp/char-shape/book/ Creating the Dataset We format the dataset to match the YOLO format. First, we merge the data, which is separated by book title, into a flat structure. #| export class Classification: def create_dataset(self, input_file_path, output_dir): # "../data/*/characters/*/*.jpg" files = glob(input_file_path) # output_dir = "../data/dataset" for file in tqdm(files): cls = file.split("/")[-2] output_file = f"{output_dir}/{cls}/{file.split('/')[-1]}" if os.path.exists(output_file): continue # print(f"Copying {file} to {output_file}") os.makedirs(f"{output_dir}/{cls}", exist_ok=True) shutil.copy(file, output_file) Next, we split the dataset using the following script: ...